Por definição, as aplicações destinadas a videoconferência incluem suporte a áudio. Na realidade, trata-se de um elemento que merece atenção especial. Ao invés do vídeo, onde a perda de um quadro na maioria dos casos não chega a ser prejudicial à aplicação, a perda de trechos de áudio em uma sessão de videoconferência pode comprometer seriamente a interatividade. Conforme Tanembaum, o ouvido é sensível a variações de som que duram milésimos de segundo, tempos inferiores aos necessários para o olho perceber variações de luz. Desta forma, um jitter de apenas alguns milésimos de segundo em uma transmissão multimídia afeta mais a qualidade do som percebido do que a qualidade da imagem percebida.
Assim como vídeo digital, o áudio sempre é obtido a partir de fontes analógicas, necessitando a conversão analógico-para-digital (A/D). A conversão de um sinal analógico em um sinal digital envolve a captura de uma série de amostras da fonte analógica. A agregação das amostras forma o equivalente digital de uma onda sonora analógica. Quanto maior a taxa de amostragem, maior a qualidade do som digital, pois foram utilizados mais pontos de referência para replicar o sinal analógico. O processo de conversão A/D pode ser dividido em três fases: amostragem, quantização e compressão.
Trata-se do processo de medir valores instantâneos de um sinal analógico em intervalos regulares [CHA 98]. O intervalo entre as amostras é determinado por um pulso de clock, e a freqüência deste clock é chamada Taxa de Amostragem.
Em 1928, Henry Nyquist provou que a representação digital de um sinal analógico poderia ser funcionalmente idêntica à onda que o originou, contanto que a taxa de amostragem fosse no mínimo o dobro da freqüência mais alta presente naquela onda (Teorema de Nyquist). Por exemplo, a voz humana, com uma freqüência máxima de 4 kHz, requer 8.000 amostras por segundo para se obter uma representação digital fiel.
Trata-se do processo de conversão das amostras contínuas ara valores discretos. O uso de oito bits por amostra é considerado satisfatório para áudio em diálogo comum, mas amostras de áudio de alta fidelidade são normalmente digitalizadas a 14 ou 16 bits por amostra, provendo uma granularidade maior.
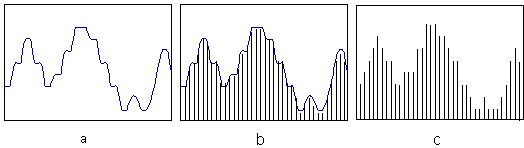
Figura X.1 - (a) Onda de Áudio. (b) Amostragem. (c) Quantização
A Figura X.1 ilustra como uma onda de áudio (a) é amostrada (b) e quantizada com 3 bits (c) em valores discretos. Convém observar que amostras com diferenças na representação analógica podem ser atribuídas ao mesmo valor discreto após o processo de quantização, devido ao número finito de possibilidades (com 3 bits, podem-se representar 8 quantizações diferentes). Esse erro, introduzido pela quantidade finita de bits, é chamado de Erro de Quantização, e pode ser detectado pelo ouvido humano se for muito grande.
Um exemplo das duas fases iniciais de conversão A/D de som são os CDs de áudio. Estes são codificados em 44.100 amostras por segundo, capturando freqüências de até 22.050 Hz (conforme o teorema de Nyquist). São usadas amostras de 16 bits cada, possibilitando 65.536 valores distintos - embora a capacidade de percepção do ouvido humano, considerando intervalos do mais baixo som audível, chegue a 1 milhão (o que comprova que CDs de áudio apresentam ruídos de quantização). Caso se considerasse a transmissão de áudio de CD, com 44.100 amostras por segundo de 16 bits, a largura de banda necessária seria
44.100 * 16 = 705,6 kbps para som mono, e
44.100 * 16 * 2 = 1,411 Mbps para som estéreo.
A transmissão de som com qualidade de CD em estéreo, conforme apresentado anteriormente, é capaz de demandar um canal T1 completo - o que comprova a necessidade de compressão de tais dados, mesmo que em videoconferência a qualidade de som utilizada seja inferior, em termos de amostras por segundo e bits por amostra.
A tabela X.1 apresenta um resumo das características das Recomendações do ITU-T relacionadas a codificação de áudio e referenciadas nas recomendações da série H. São apresentados o tipo de algoritmo usado por cada codec, a taxa de bits a qual se destina, a freqüência de trabalho, o delay típico entre dois pontos (exclusivamente do codec, sem considerar o canal) e aplicações típicas. Maiores detalhes sobre os codecs de áudio serão fornecidos a seguir, em suas respectivas descrições.
Tabela X.1 - Codecs de Áudio do ITU-T
|
Recomendação
(Ano de Aprovação) |
Algoritmo
|
Taxa de Bits (kbit/s)
|
Largura de Banda (Hz)
|
Delay entre Pontos (ms)
|
Aplicação
|
|
G.711(1972)
|
PCM
|
56, 64
|
300 - 3,4k
|
< 1
|
Telefonia GSTN, videoconferência H.320/H.323
|
|
G.722(1988)
|
Sub-ADPCM
|
48, 56, 64
|
50 - 7k
|
< 2
|
Telefonia e Videoconferência ISDN
|
|
G.723.1(1995)
|
ACELP - 5,3MP-MLQ - 6,3
|
5.3, 6.3
|
300 - 3,4k
|
67-97
|
Videotelefonia GSTN,Telefonia H.323,VoIP (básico)
|
|
G.728(1992)
|
LD-CELP
|
16
|
300 - 3,4k
|
< 2
|
GSTN,Videoconferência H.320
|
|
G.729(1995)
|
CS-ACELP
|
8
|
300 - 3,4k
|
25-35
|
Telefonia GSTN, Modem GSTN, Videotelefonia H.324 GSTN
|
|
G.729 - A(1996)
|
CS-ACELP
|
8
|
300 - 3,4k
|
25-35
|
Modem GSTN, Videotelefonia H.324 GSTN
|
G.711
A recomendação G.711, editada inicialmente em 1972, especifica a modulação de sinais de freqüência de voz por código de pulso, por isso também é referenciada como PCM (Pulse Code Modulation). A codificação é realizada a uma taxa nominal de 8000 amostras por segundo (8 kHz), utilizando 7 ou 8 bits por amostra. A taxa de transmissão dessa codificação resulta em 7 x 8000 = 56 kbit/s ou 8 x 8000 = 64 kbit/s. Novamente de acordo com o teorema de Nyquist, a especificação G.711 pode codificar freqüências de áudio entre 0 e um máximo de 4 kHz.
As regras de codificação são referenciadas como A-law (utilizado na Europa) e m-law (utilizado na América). Apesar do formato resultante da codificação se parecer com uma função logarítmica, a conversão dos sinais é definida por tabelas de decisão. São especificadas quatro tabelas diferenciadas, para valores A-law / m-law, tanto positivos quanto negativos.
O áudio de entrada é dividido em segmentos, cada um deles usando quantidades diferentes de intervalos como valores nas tabelas de decisão. A maior parte dos segmentos contém 16 intervalos, e o tamanho dos intervalos dobra de segmento a segmento. A Figura 4.2 mostra três segmentos com quatro intervalos em cada um. A codificação m-law usa 8 segmentos de 16 intervalos cada nas direções positiva e negativa, começando com um tamanho de intervalo 2 no segmento 1, e incrementando até um tamanho de intervalo 256 no segmento 8. A codificação A-law usa 7 segmentos. O menor (de tamanho de intervalo 2) contém o dobro de intervalos dos demais (32 intervalos). Os seis segmentos restantes contém 16 intervalos cada, dobrando de tamanho de 4 (segmento 2) até 128 (segmento 7). A codificação A-law, usada internacionalmente, representa sinais menores com maior fidelidade que a m-law. A recomendação também apresenta tabelas de conversão m-law <=>A-law.
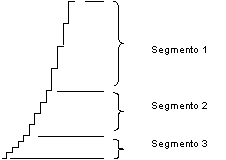
Figura X.2 - Segmentação de uma Onda de Áudio codificada com PCM
A partir da técnica PCM, foram propostas algumas implementações diferenciadas. Os codificadores e decodificadores DPCM e ADPCM funcionam baseados na expectativa de que as amostras de áudio vizinhas sejam semelhantes entre si. Assim, o codificador DPCM calcula a diferença entre o valor efetivo da amostra e o valor provável (com base na comparação pelas amostras anteriores), e realiza a codificação PCM apenas sobre o resultado da diferença. Desta forma, a taxa de bits gerada é inferior à gerada pela recomendação G.711.
O método ADPCM emprega uma combinação de adaptações de quantização e predição sobre o método DPCM. Adaptação, nesse contexto, significa reação a alterações no nível e no espectro do sinal de áudio de entrada. Existem duas formas de realizar a predição adaptativa :
G.722
A recomendação G.722, proposta em 1988, descreve as características de sistemas de codificação de áudio (50 a 7000 Hz), usados em diversas aplicações de conversação de alta qualidade. O sistema de codificação utiliza a técnica SB-ADPCM (sub-band adaptive differencial pulse code modulation), a uma taxa de 64 kbit/s. Nesta técnica, a banda de freqüência é dividida em duas sub-bandas : alta (H) e baixa (L). Os sinais em cada sub-banda são codificados usando ADPCM. O sistema possui três modos de operação para codificação do áudio a 7 kHz, com variações na taxa de bits e na taxa de bits do canal de dados auxiliar (para prover a taxa efetiva de 64 kbit/s usando os bits da sub-banda inferior. Os modos de operação disponíveis são apresentados na Tabela X.2.
Tabela X.2 - Modos de operação da recomendação G.722
|
Modo
|
Taxa de bits de áudio a 7 kHz codificado
|
Taxa de bits do canal de dados auxiliar
|
|
1
|
64 kbit/s
|
0 kbit/s
|
|
2
|
56 kbit/s
|
8 kbit/s
|
|
3
|
48 kbit/s
|
16 kbit/s
|
Conforme a recomendação, independente do modo de operação escolhido para a implementação, é sugerido que o modo 1 sempre seja implementado, mesmo que de forma adicional ao(s) modo(s) escolhido(s).
G.723.1
A Recomendação G.723.1, editada em 1996, especifica uma representação codificada para compressão de diálogo ou outros sinais de áudio em serviços multimídia a taxas de bits muito baixas, com o objetivo de servir como suporte de áudio à recomendação H.324. As taxas de bit associadas são 5,3 kbps (mais flexível) e 6,3 kbit/s (melhor qualidade). A codificação do áudio é realizada em quadros de 30 milissegundos. O formato G.723.1 foi selecionado pelo Fórum VoIP (Voice over IP) como o codec base para aplicações de Voz sobre IP a baixas taxas de bit [CHA98].
Esse codificador foi projetado para operar com sinais digitais, obtidos a partir da filtragem da fonte analógica (a filtragem é definida na Recomendação G.712), e então amostradas a 8000 Hz e convertidas para PCM em 16 bits para a entrada do codificador. A saída do decodificador realiza o processo inverso. O princípio da codificação é a predição análise-por-síntese, seguida de mecanismos para minimizar erros perceptíveis. O codificador trabalha em blocos (quadros) de 240 amostras cada (8000 amostras por segundo x 0,030 segundos).
Os componentes do algoritmo apresentado na Recomendação são definidos em forma de função na própria Recomendação, que inclui também os diagramas de bloco (representação visual da interação dos componentes) para cada componente.
G.728
A recomendação G.728, publicada em 1992, provê codificação de áudio a 3,1 kHz para transmissão a 16 kbps. É normalmente utilizada em sistemas que operam a 56 ou 64 kbps. Com requerimentos computacionais bem mais altos, o padrão G.728 provê a qualidade do padrão G.711 - a um quarto da taxa de transmissão. O algoritmo utilizado para a codificação é o LD-CELP (low-delay excited linear prediction).
G.729 e G.729a
As recomendações G.729 e G.729a, aprovadas respectivamente em 1995 e 1996, especificam a codificação de sinais de áudio na faixa de 3,1 kHz, para transmissão a 8 kbps. A recomendação G.729A exige menos poder computacional que a G.729; ambas possuem latência menor que a G.723.1. Existe uma boa expectativa do uso da recomendação G.729A para transmissão de áudio compactado em redes sem fio (wireless).